

Zividのカメラは、構造化光(Structured Light)と呼ばれる技術を採用しています。これは、プロジェクターとカメラを隣接して配置し、対象物に光を投影すると同時に、その様子を撮影する手法です。
Zividで働き始めて間もなく、私は「構造化光によって、どのようにして物体の詳細な3D画像を生成できるのだろうか」と理解したいと思うようになりました。
異なるパターンの光を物体に照射することで、なぜその物体の幾何学的な形状についての情報が得られるのでしょうか。
その仕組みを解明するために、私は **Blender** 上で簡単なテストシーンを作成することにしました。そこでは、カメラとプロジェクターを少し離して配置しています。
この投稿で使用したシーンとソースコードも公開されています。
Blenderで基本的なプロジェクターとカメラを設定する
カメラは、通常のBlenderのカメラを使用します。
一方、プロジェクターは、画像を色情報として入力したライト を用いて作成します。
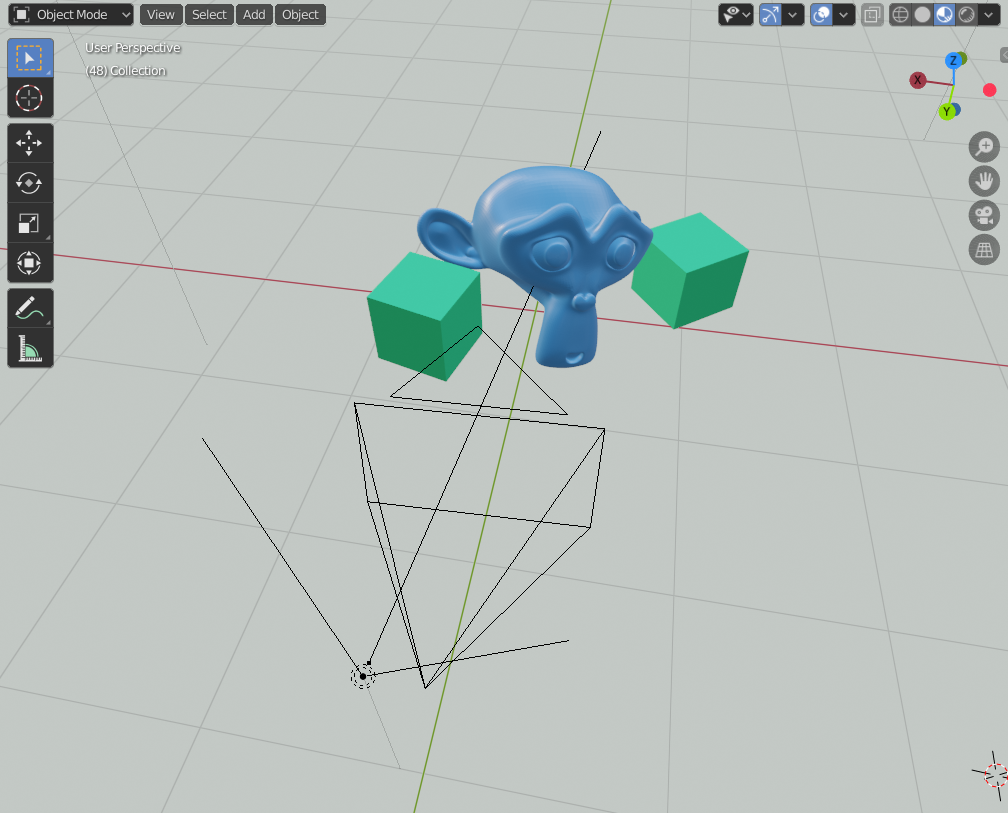
ライトへの画像入力は、Blenderのノードシステムを使用して行います。
具体的には、Emission(放射)ノードをライト出力に接続し、さらにImage(画像)ノードをEmissionノードの色入力へ接続します。
また、画像ノードのVector(ベクトル)入力には、テクスチャ座標のNormal(法線)を設定する必要があります。これにより、画像のどのピクセルを使用するかが決定されます。
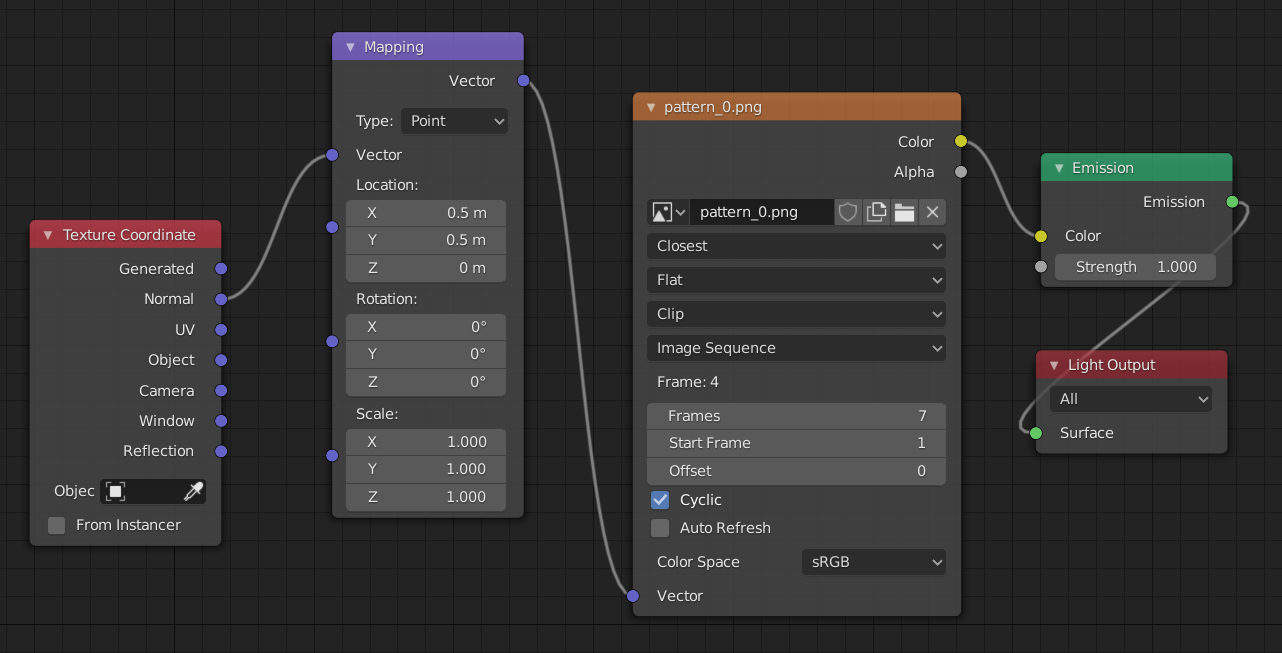
しかし、この方法で投影すると、投影結果に多少の歪みが生じます。
以下は、平面に対して真下へ直接投影した際の様子です。
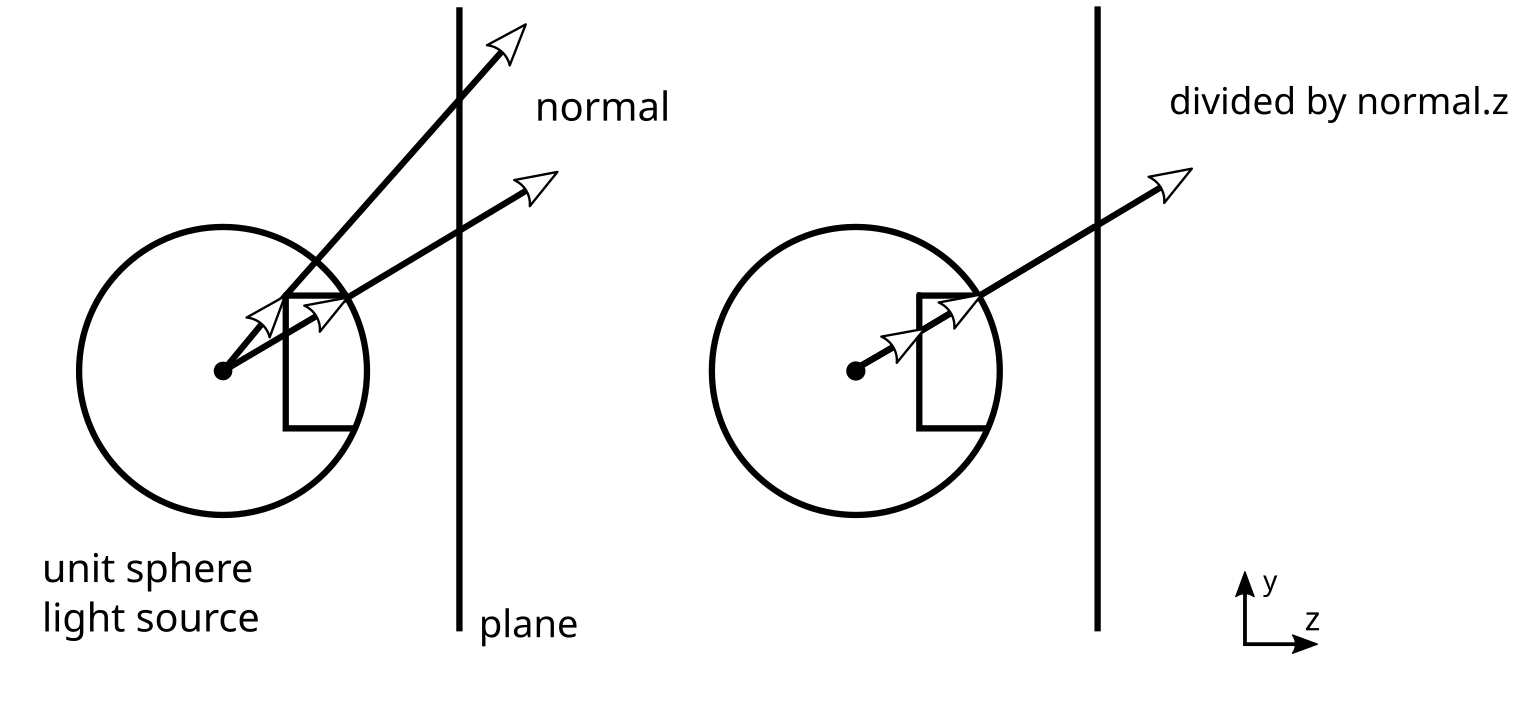
この問題は、法線ベクトル(normal)が単位球(unit sphere)上から投影されていることによって生じます。
ある y 値 に対応する単位球上の線を描き、それらの線が平面スクリーン上にどのように投影されるかを考えると、平面に到達する光線がそれぞれ異なる y 座標 に位置することが分かります。
これは、各光線が平面に到達するまでに進む距離が異なるためです。
この問題を補正するために、平面に到達する光線の法線ベクトルを、その z 値で割ることができます。こうすることで、テクスチャ座標として期待される適切な y 値を得ることができます。
Blender のノード構成では、この z 値による除算 は、Vector Separate(ベクトル分離)ノード と Vector Divide(ベクトル除算)演算 を使用することで実現できます。
その結果、実際のプロジェクターによる投影により近いもの**を得ることができます。
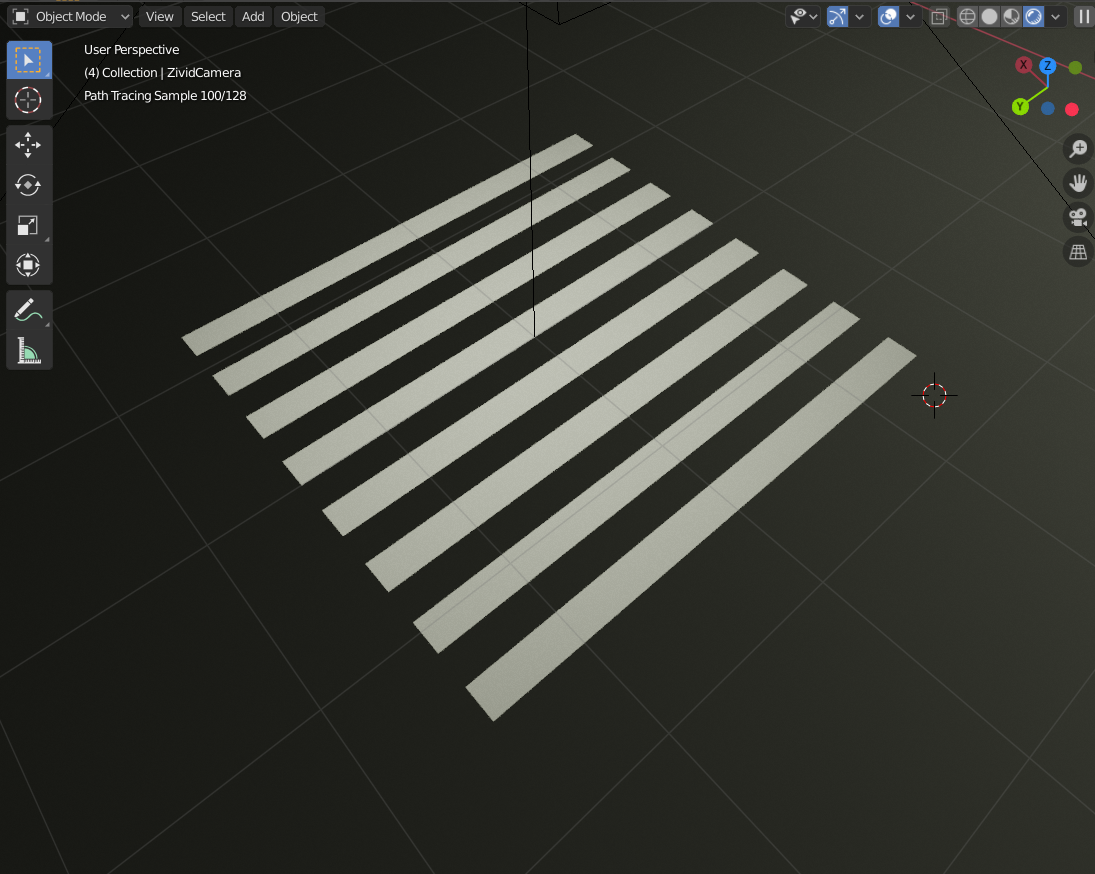
もちろん、実際のプロジェクターには、レンズによるピントのずれ(デフォーカス)や歪み(ディストーション)が存在します。
私が Blender で作成したプロジェクターは、むしろ理想的なピンホールプロジェクターに近いものです。これは、ピンホールカメラに対応する「プロジェクター版」と考えることができます。
このプロジェクトでは、完全なピンホールプロジェクターで十分でした。なぜなら、私の目的は、構造化光がどのように機能するのかを理解することであり、実際のシステムにおけるあらゆる課題を解決する方法を学ぶことではなかったからです。
構造化光の基本原理
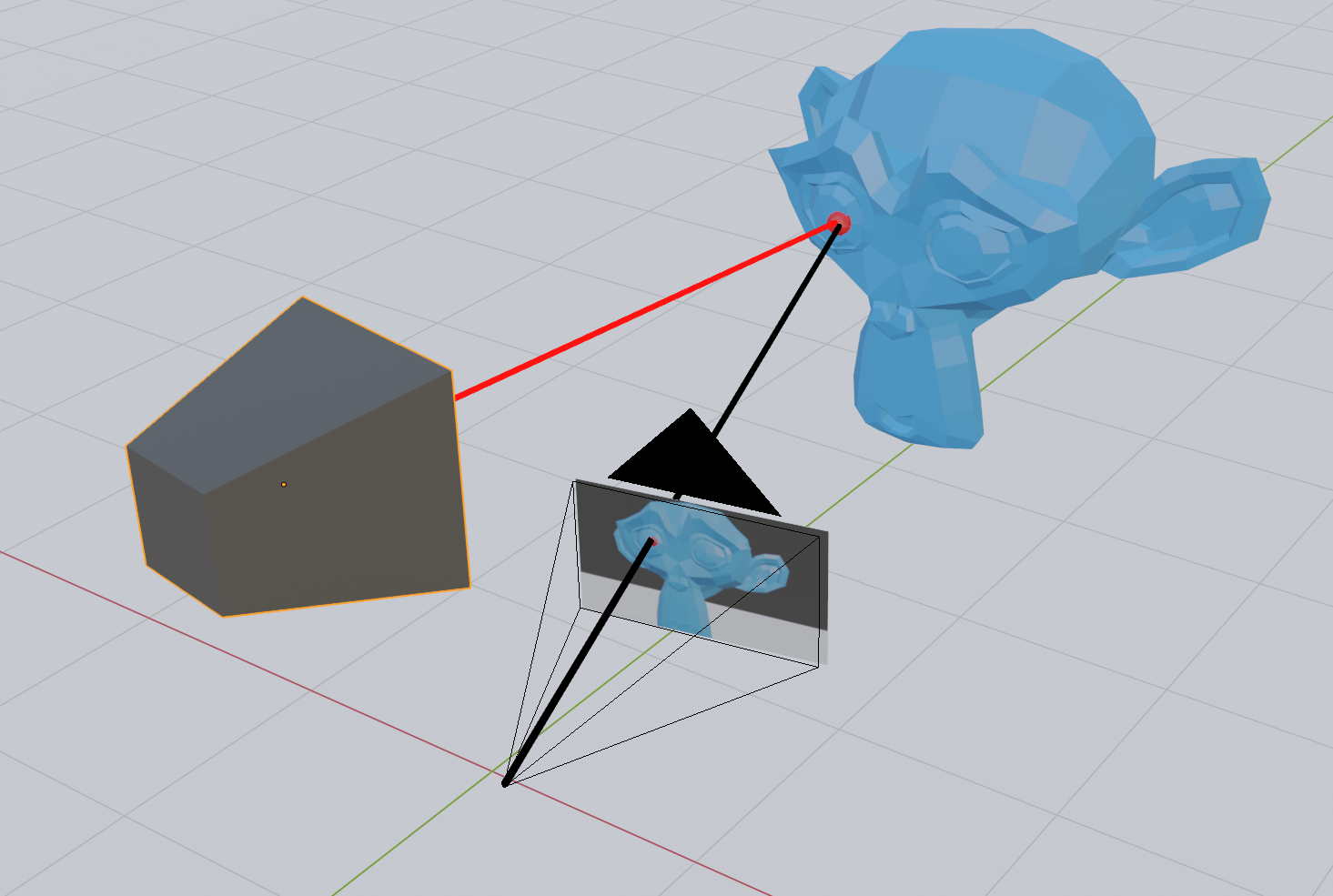
構造化光によってロボットが3次元(3D)で物体を認識できるのは、カメラとプロジェクターの間に存在する位置のずれ(オフセット)と角度差を利用しているためです。
これは、私たちが両眼視(ステレオビジョン)によって3Dを認識する仕組みによく似ています。実際、このステレオビジョンは多くの3Dカメラでも利用されています。
ステレオビジョンでは、2台の通常のカメラでそれぞれ画像を撮影し、両方の画像に共通して現れる特徴点を探します。
もし同じ点を2つの画像内で特定できれば、その点の位置を求めるために必要な情報が得られます。少なくとも、カメラに対する相対的な位置は算出できます。
デジタルステレオカメラでは、両方の画像内で対応する点が見つかると、それぞれの画像上のピクセル座標が分かります。
その3D座標を求めるには、各カメラの焦点からそのピクセル座標を通る直線を引き、それらが交わる点、あるいは最も近づく点を求めればよいのです。

構造化光では、この2台のカメラのうち1台をプロジェクターに置き換えます。
これにより、2枚の画像の中から共通の特徴点を検出する工程を省略できます。なぜなら、プロジェクターを使って特定の1点だけを照射し、カメラ側ではその点だけを検出すればよいからです。
構造化光では、この2台のカメラのうち1台をプロジェクターに置き換えます。
これにより、2枚の画像の中から共通の特徴点を検出する工程を省略できます。なぜなら、プロジェクターを使って特定の1点だけを照射し、カメラ側ではその点だけを検出すればよいからです。
しかし、この方法で各点を1つずつ照射すると、非常に長い時間がかかってしまいます。
プロジェクターの各ピクセルごとに1枚ずつ画像を撮影する必要があるためです。
画像に約200万画素あるとすると、毎秒60フレーム(60 FPS)で撮影できるカメラを使ったとしても、撮像には数時間を要してしまいます。
そこで実際には、シーンの幾何学的な性質を利用した、いくつかの工夫されたパターンを投影する方法が採用されます。
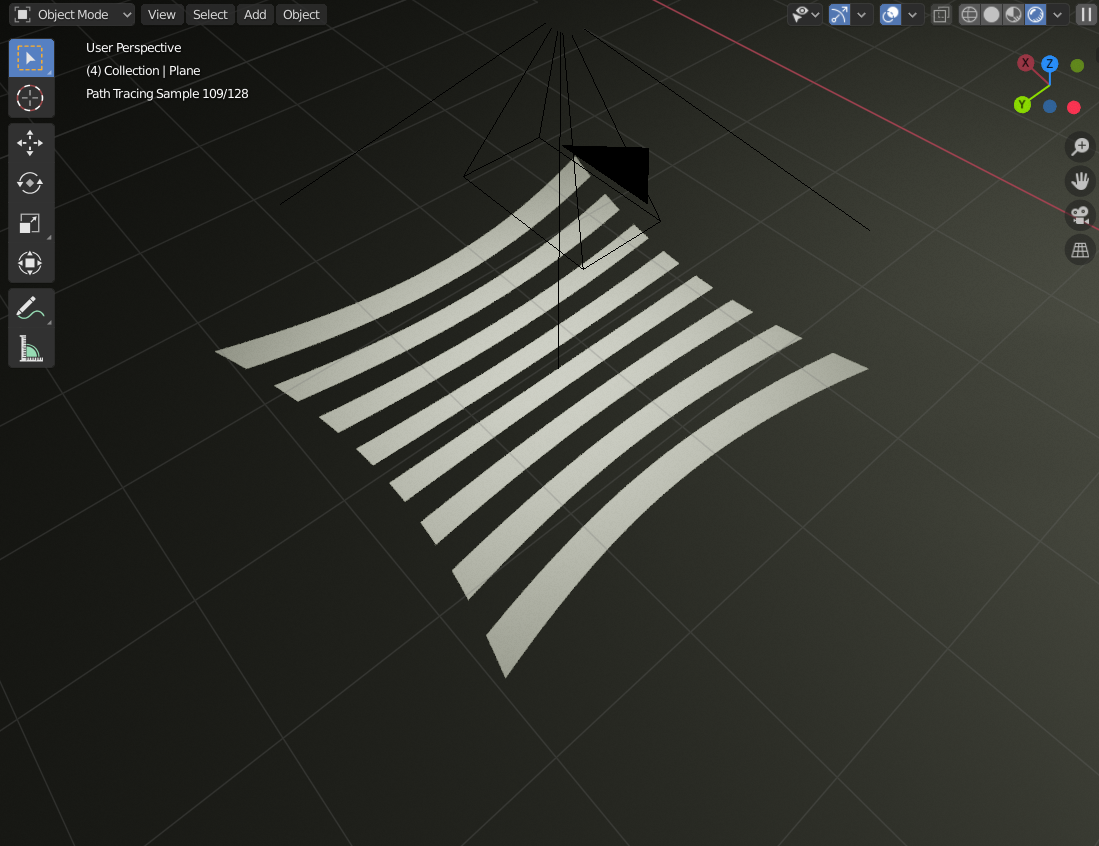
まず、シーンに**水平な縞模様**を投影した場合を考えてみましょう。
このとき、カメラから見たシーンには興味深い現象が見られます。
次に、これを**垂直な縞模様**の場合と比較してみます。
すると、サルのメッシュ(monkey mesh)の位置が変わっても、水平な縞模様は常に同じ場所に現れることに気付くでしょう。
一方で、垂直な縞模様のピクセル位置は、サルの位置によって変化します。
なぜこのような違いが生じるのかについては、後の投稿でもう少し詳しく説明する予定です。
簡単に言えば、カメラとプロジェクターのオフセット自体が水平方向に配置されているため、水平な縞模様は移動しないのです。
プロジェクター上の各水平線は、カメラ上のいわゆるエピポーラ線(epipolar line)に対応しています。
この観察結果に基づくと、現時点では次のように考えることができます。
水平線は、撮影対象の奥行き(深度)に関する情報を与えない。
垂直線は、奥行きに関する情報を与える。
言い換えれば、プロジェクターから必要となる重要な情報は、ピクセルの x 座標だけであるように見えます。
プロジェクターの x 座標 が分かれば、その座標に対応する平面を定義でき、その平面とカメラから伸びる視線との交点を求めることができます。
一方で、プロジェクターのピクセルの y 座標 から得られる情報は、すでにカメラ側のピクセルの y 座標 に含まれていると考えられます。
直線と平面の交差を利用する手法
プロジェクターのピクセルの y 座標には追加の情報が含まれていないため、カメラで観測された点の3次元位置は、カメラのピクセルから伸びる視線と、プロジェクター上の x 座標に対応する平面との交点を求めることで算出できます。

つまり、カメラ画像上のあるピクセルについて、そのピクセルの色からプロジェクター上の x 座標を特定する方法さえあれば十分なのです。
プロジェクターの x 座標が分かれば、それに対応する平面を定義でき、その平面とカメラからの視線との交点を求めることができます。
バイナリコードパターン
プロジェクターの x 座標 を画像のピクセルに符号化する方法はいくつか存在します。
もし完全に白いシーンを撮影するのであれば、プロジェクターのピクセルの色を利用して、特定の x 座標を表現することができます。
しかし、シーン内に色のついた物体が存在する場合、投影した色が正しくカメラに戻ってこないことがあり、その結果、一部の情報が失われる可能性があります。
また、2枚の画像を撮影し、それらの差分(diff)を利用して必要な情報を符号化する方法もあります。
しかし、この方法も、シーン内の物体が符号化に使用した色の光を完全に吸収してしまう場合には、適切に機能しない可能性があります。
3つ目の方法として、完全な白黒パターンを用いた複数枚の画像を撮影するという手法があります。
最も単純な方法は、おそらくバイナリパターン(2進パターン)を使用することです。
これらのパターンは、読み取ることでプロジェクター上の x 座標として解釈できる情報を含んでいます。
具体的には、白黒領域からなる7枚の画像で構成されます。
.png?width=800&name=MicrosoftTeams-image%20(5).png)
画像内のあるピクセルの**バイナリコード**は、次のように求められます。
1. まず、すべての画像において、同じピクセル位置の値の最小値と最大値を求めます。
2. 次に、その最小値と最大値の平均値を計算します。
3. そして、ある画像におけるそのピクセルの値を、この平均値と比較します。
ピクセル値が平均値より明るい場合は、そのビットを 1 に設定します。
それ以外の場合は、そのビットを 0 に設定します。
最後に、この2進数(バイナリコード)を10進数へ変換することで、プロジェクター上の x 座標 を得ることができます。

実際の結果を見ると、各パターンは完全には一致しておらず、画像内にはいくつかの黒い線が現れています。
しかし、全体としては十分に良好な結果が得られており、このまま先の処理を進めることができます。
ピクセルから3次元点への変換
カメラのピクセルから伸びる視線と、プロジェクターの x 座標 に対応する平面との交点を計算するには、まずピクセル座標を3次元空間内の点へ変換するための行列を用意する必要があります。
ここでは、その目的のために、コンピュータグラフィックスで一般的に使用される 4×4 の同次変換行列 を利用します。
幸いなことに、これらの行列は Eigen や glm といった既存の線形代数ライブラリを使えば、比較的簡単に構築できます。
カメラの視線とプロジェクターの平面との交差
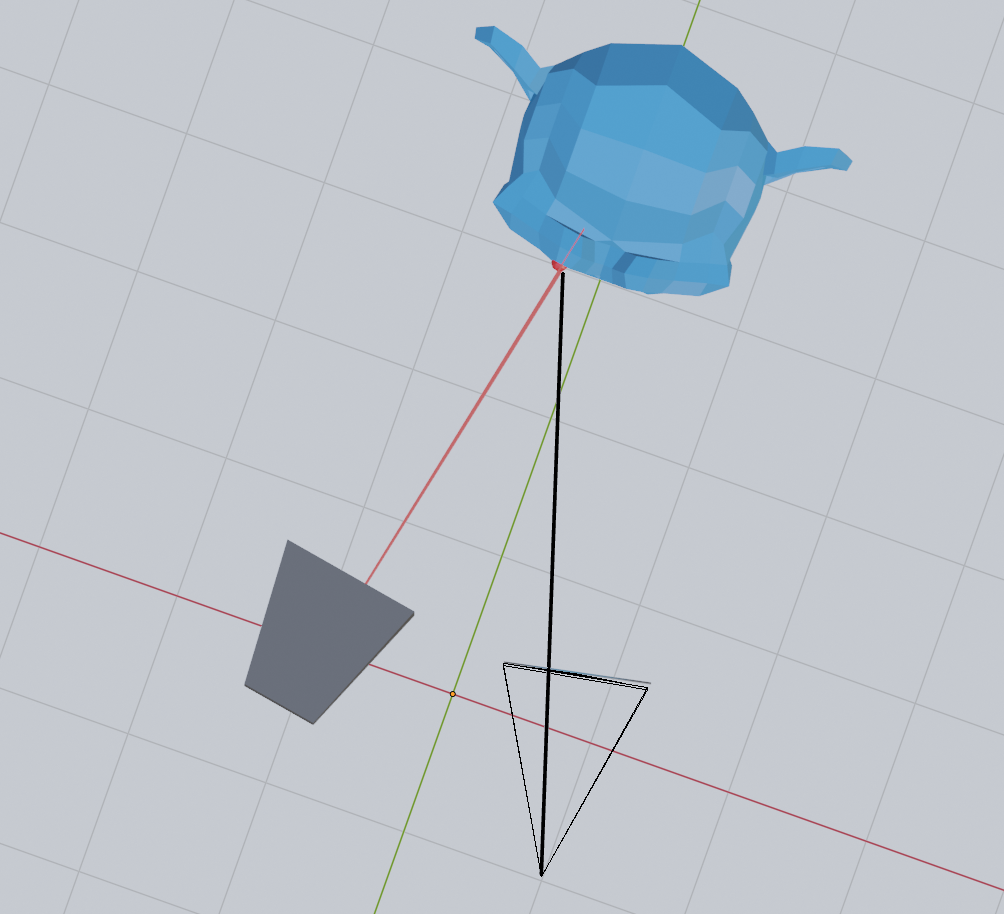
これで、カメラのピクセルから3次元空間上の点を求められるようになりました。
次に、そのピクセルを通る視線(レイ)を作成します。
もちろん、そのピクセルの z 値 は分かりません。
そこで、2つの z 値を仮定し、それぞれに対応する点を求め、それらを結ぶことでカメラの視線を定義します。
この視線は、y 軸に平行で、プロジェクターの x 座標を通る平面と交差させることができます。
この問題を2次元で考えると、単純な直線同士の交点計算になります。
したがって、2次元における直線の交点を求めることで、カメラの視線上のどの位置で3次元の交差が起こるのかを計算できます。
その後、得られた z 値 を画像として保存できます。
ここで注意すべき点として、使用した行列の規約では z 値は負の値 になります。
また、私は 3.0 で割る処理 を行っていますが、これは、その方がシーン内の物体までの実際の距離をより適切に表現できると分かっていたためです。
このようにして得られた深度画像は、次のようになります。

しかし、私たちが求めているのは、単なる深度画像ではありません。
私たちの目的は、これらの画像から3Dモデルを生成することです。
3Dモデルを生成するために、x、y、z の座標値と色情報をまとめて保存する新しい関数を作成します。
色情報は、各画像における最大値と最小値の平均として計算できます。
この平均値は、
* プロジェクターがシーン全体を照らしているときの色
* プロジェクターから光が照射されていないときの色
の中間に相当します。
生成された XYZ ファイル をビューアーで読み込みます。

誤った行列を使用していたために、一日中ひどい結果ばかりを見続けた後、この結果が画面に表示されたときは本当に嬉しかったです。
もちろん、まだ除去すべきノイズは多く残っていますし、本来は厚みのないはずの床に厚みが生じるといった奇妙な現象も見られます。
しかし、それらについては今後対処していく予定です。
現時点では、この結果には十分満足しています。
コード例を含む完全な記事については、元の記事をご覧ください。

Zivid、透明イメージング機能を備えた3Dカメラのシリーズ最新作を一挙発表

精密度と真度 - 細部を捉え、現実に忠実であること
